In order to gain a better understanding of the possible outcomes of the upcoming, and highly critical, New York primary, our team at Diktio Labs took a different approach and left the polls behind. Instead, we monitored and analyzed activity on Twitter.
Between April 11 and April 15, 2016, we analyzed 151,965 tweets by 36,703 accounts containing the hashtag #NYPrimary, with the purpose of identifying key influencers, topic clusters, and of course the popularity of candidates in the Empire State.
#Trump2016 vs. #FeelTheBern
Despite the fact that Hillary Clinton is more widely considered to emerge victorious from the NY primary, and eventually become the candidate of the Democrats, Bernie Sanders and his supporters have a much stronger online presence. In fact, Sanders is the only candidate, thanks to his active supporters, who has a slight chance of diluting Trump's online dominance.

Sanders supporters tweet vigorously, hence they represent over 50% of the Top 30 most active accounts. (We have manually removed bots.)


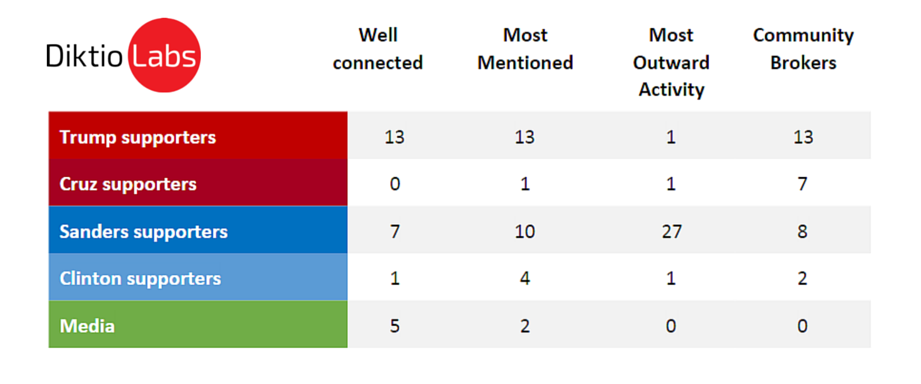
For most mentioned, there is only one account that makes it to the list for Cruz, four supporting Clinton, while the rest of the top 30 are Trump and Sanders supporters.
Most outward activity: accounts producing the most tweets in support for a candidate seem to be overwhelmingly pro-Sanders. However, most of them do not make it into the well-connected list because they are rather poorly embedded into Twitter conversations around the election.
Community brokers are accounts that bridge conversations about their preferred candidates between groups of users who would otherwise not communicate. They mostly engage in debated topics by following conversations in other camps and replying to those.
In our analysis, we also examined the top 30 hashtags mentioned in order to gain a better understanding of the topics surrounding the New York primary.

Trump’s campaign-related hashtags receive the most attention, followed by Sanders. Clinton is referenced mostly through the hashtag #ImWithHer, rather than nominally. The supporters of Cruz mention their preferred candidate much less than the other supporters.
The hashtag #NeverTrump is considered the only negative tag in the Top 30.
In order to identify the top 30 most mentioned (interesting/debated/adored/hated) candidates, we took a look at candidate mentions, on a user level. Example: how many users talked about candidates, during the analyzed time frame. We have visualized our results on a network map. The size of nodes and labels indicates the number of users mentioning the name of the candidate, while the connecting lines (edges) reflect how many users talked about both candidates. The color of the node indicates party affiliations: red is for Republicans, blue is for Democrats.

The most mentioned candidate was Donald Trump with more than 2,000 more users talking about him than about Bernie Sanders. Kasich was the least mentioned candidate. Clinton and Cruz are mentioned almost by the same number of users, which is less than half the number of users mentioning Trump.
In terms of users talking about two candidates, the biggest overlap is between Clinton and Sanders, followed by Trump and Cruz. The difference is more than 1,000 users. The remaining combinations were not so frequent apart from that of Clinton and Trump, mentioned by two percent of the users using the hashtag #NYPrimary.
This interactive, clickable and zoomable network map, (filtered to indicate top connections only) depicts what hashtags were mentioned together within the same tweet in our dataset. The thicker the edge, the more often the two hashtags were mentioned together. Node and label sizes indicate how often the given hashtag was mentioned together with other hashtags [network science metric: weighted degree].
Over 19% of the tweets associated #NYPrimary with #Trump2016, and almost 16% with #FeelTheBern. #ImWithHer: 8.6% of tweets. The different color clusters depict various topics around the NY Primary. Dark orange hashtags represent upcoming primaries: #PAPrimary, #MDPrimary, #DEPrimary, #CTPrimary, #RIPrimary, dark blue ones are the most associated hashtags with New York, while the light orange hashtags with the Democratic party.
Will the domination on Twitter manifest in the elections?
So far, our analyses clearly show that Trump and Sanders dominate Twitter conversations about the NY primary, each in their own community of supporters and opponents. The NY primary are expected to have a higher than average turnout in the state of New York, which might bring surprises, at least for the Democrats, where, according to polls, the two candidates are in a tight race for the win.
Please bear in mind that an online analysis does not intend to replace the offline polls or in itself cannot predict the results of the actual elections. Our experience in political analysis suggests that smaller parties and “anti-establishment” candidates tend to be more active on social media. The NY primaries are further complicated by the fact that the registration was over six months ago, thus however successful a candidate is on social media now, it might be too late to turn the popularity gained into actual votes. Given the race is not over between the candidates, there is a lot to learn in the forthcoming months.
Are you interested in the methods behind our analysis, and how you could benefit from online community mapping? Reach out to us via email at info@diktiolabs.com









